Estrazione efficiente di testo da PDF con modelli linguistici di visione —— perché olmOCR cambia le carte in tavola
Scopri come olmOCR trasforma l'elaborazione dei PDF con l'estrazione di testo basata sull'IA, l'efficienza dei costi e l'innovazione open-source.
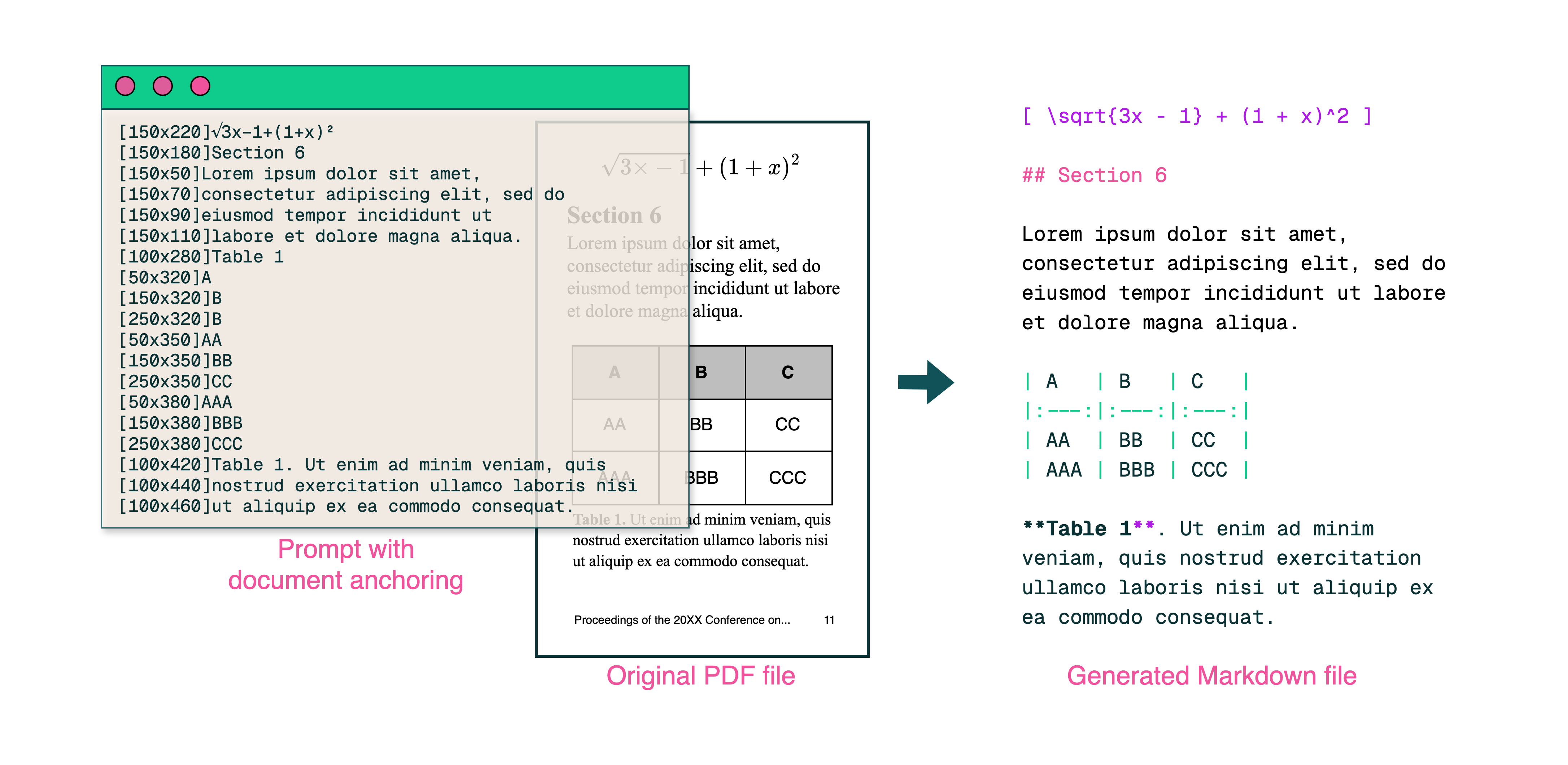
Didascalia: la pipeline end-to-end di olmOCR converte PDF complessi in testo Markdown strutturato a 1/32 del costo di GPT-4o.
La sfida nascosta dei PDF: perché il testo semplice è importante
I modelli linguistici prosperano con testo pulito, ma i PDF sono il nemico-amico per eccellenza. Progettati per la stampa, non per l'analisi, scompaginano le posizioni del testo, seppelliscono le tabelle in codice binario e trasformano le equazioni in enigmi visivi. I tradizionali strumenti OCR? Spesso mancano la formattazione, faticano con layout multi-colonna o costano una fortuna.
Entra in olmOCR: un toolkit open-source che combina modelli linguistici di visione (VLM) con ingegneria intelligente per decifrare il codice PDF. Analizziamo perché sviluppatori e ricercatori ne parlano con entusiasmo.
5 motivi per cui olmOCR supera gli altri strumenti
-
Efficienza dei costi difficile da ignorare
 Elabora 1 milione di pagine per $190: questo è 32 volte più economico delle API batch di GPT-4o. Come? Ottimizzando su 250.000 pagine diverse (articoli accademici, documenti legali, persino lettere manoscritte) e ottimizzando l'inferenza con SGLang/vLLM.
Elabora 1 milione di pagine per $190: questo è 32 volte più economico delle API batch di GPT-4o. Come? Ottimizzando su 250.000 pagine diverse (articoli accademici, documenti legali, persino lettere manoscritte) e ottimizzando l'inferenza con SGLang/vLLM. -
Magia Markdown Niente più incubi di regex. olmOCR produce Markdown pulito con:
- Equazioni preservate (
E=mc²) - Tabelle che rimangono tabelle
- Ordine di lettura corretto per layout complessi
- Equazioni preservate (
-
Pipeline "batterie incluse"
python -m olmocr.pipeline ./workspace --pdfs your_file.pdfScala da 1 a 100+ GPU senza problemi. La gestione degli errori integrata affronta i comuni problemi dei PDF, come la corruzione dei metadati.
-
Open Source, zero scatole nere Pesi, dati di addestramento (sì, tutte le 250.000 pagine!) e codice sono pubblici. Costruito su Qwen2-VL-7B-Instruct: nessuna dipendenza proprietaria.
-
Superiorità comprovata dall'uomo
Nei test ciechi contro Marker, GOT-OCR 2.0 e MinerU:- Vince il 61% dei confronti
- Ottiene ELO >1800 (Gold Standard)
Sotto il cofano: come abbiamo costruito olmOCR
Document Anchoring: il segreto del successo
 Didascalia: contesto testo + immagine = estrazione accurata.
Didascalia: contesto testo + immagine = estrazione accurata.
Usiamo il testo/metadati dei PDF per "ancorare" i VLM durante l'addestramento:
- Estrai blocchi di testo e regioni di immagine
- Combinali nei prompt del modello
- Lascia che GPT-4o generi etichette "gold standard"
Risultato? Un modello che capisce sia cosa dice il testo sia dove appartiene.
Addestramento per il mondo reale
- Dataset: 60% articoli accademici, 12% brochure, 11% documenti legali
- Hardware: ottimizzato per GPU NVIDIA, 90% di consumo energetico inferiore rispetto a configurazioni comparabili
- Fine-Tuning: Qwen2-VL-7B-Instruct adattato per "conversazioni" sui documenti
Prova olmOCR in 3 minuti
- Installa
git clone https://github.com/allenai/olmocr && cd olmocr pip install -e . - Esegui su un PDF di esempio
python -m olmocr.pipeline ./demo_output --pdfs tests/gnarly_pdfs/horribleocr.pdf - Controlla il Markdown
Apri
./demo_output/horribleocr.md: vedi tabelle, equazioni e flusso di testo intatti!
Considerazioni finali
olmOCR non è solo un altro strumento: è un cambio di paradigma. Combinando i VLM con un'ingegneria trasparente, rende l'estrazione di testo di alta qualità accessibile a tutti. Che tu stia costruendo un corpus di ricerca o automatizzando l'elaborazione delle fatture, questo toolkit appartiene al tuo stack.
Prossimi passi
- ⭐ Metti una stella al repository GitHub
- 📊 Confronta gli output utilizzando lo strumento interattivo
- 💬 Partecipa alla discussione su Hugging Face
Trasformiamo il dolore dei PDF in guadagno di testo semplice! 🚀