*****
"Free OLM OCR has revolutionized how I handle documents. Converting scanned files to editable text with such accuracy has saved me countless hours of manual transcription."
Sarah Johnson
Content Manager
Tech Solutions Inc.
Extract text, images, tables, and formulas from images, PDFs, and scanned documents. Supports multiple languages and JSON output. with OLM OCR. Powered by OLM and enhanced with AI, convert scanned documents into editable, searchable text in seconds, including table OCR and handwriting OCR.
Comienza gratis con nuestra herramienta OLM OCR. Extrae texto de tus primeras 3 páginas sin costo.
OLM OCR combina una velocidad inigualable con una precisión líder para documentos complejos, multilingües y multimodales.
Provides Doc-as-prompt functionality, generating highly structured output for easy integration and processing.
OLM OCR seamlessly processes documents in a wide array of languages and formats, including images, PDFs, and handwritten notes, thanks to its advanced handwriting OCR.
Each example demonstrates OLM OCR's capability to provide best-in-class accuracy in text extraction, including table OCR and handwriting OCR.


Con la confianza de miles de usuarios en todo el mundo por sus servicios OCR precisos y confiables
"Free OLM OCR has revolutionized how I handle documents. Converting scanned files to editable text with such accuracy has saved me countless hours of manual transcription."
"The multilingual support is incredible. I can extract text from documents in multiple languages with remarkable precision. It's been a game-changer for our international business."
"The structured output feature is exactly what we needed for our document processing pipeline. The JSON format makes integration with our systems seamless."
OLM OCR is a document understanding API that extracts text, images, tables, and formulas from PDFs, images, and scanned documents.
Typical uses include research extraction, archive digitization, document ingestion, customer operations, and searchable knowledge bases.
Key features include text extraction, layout-aware parsing, table and formula handling, multilingual recognition, and JSON output.
It focuses on document understanding rather than plain character recognition, so it can preserve richer structure from complex documents.
Yes. It is designed for documents with tables, formulas, multi-column layouts, and mixed visual content.
Yes. OLM OCR uses AI models to understand document content and produce structured extraction results.
Explore our latest articles about OCR technology, tips and best practices for text extraction from images, including table OCR and handwriting OCR.
See how OLM OCR turns scanned PDFs and images into clean, structured, editable text.
Leer más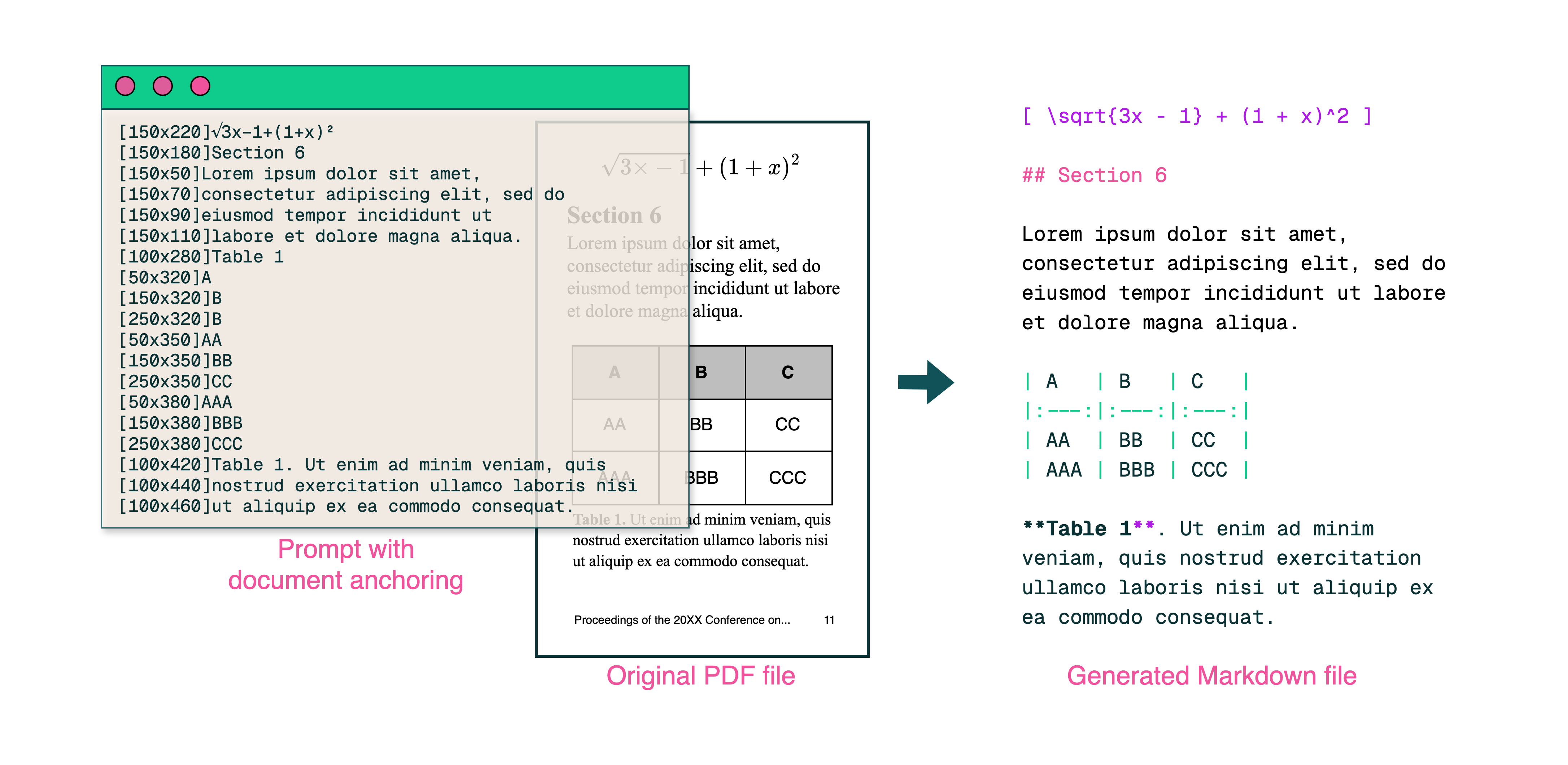
Discover how OLM OCR transforms PDF processing with AI-driven text extraction.
Leer más
Deploy olmOCR locally and build a private PDF processing service.
Leer más